


What are the top features of PDF Extractor?
PDF Extractor has been helping agents and asset managers, among others, to extract data from CRE investment brochures. But what are the main stand out features that mean businesses are choosing to replace manually extracting data with PDF Extractor?
Volume of data points extracted
At the time of writing, PDF Extractor captures over 70 data points from investment brochures including; tenancy schedules, yields, capital values, size and location information. The full list of currently extracted fields is available here, and the algorithms are being continually trained to extract new data points in response to client requests.
Time taken to extract data from each PDF
It takes a matter of seconds to extract data from a 20 page PDF brochure, which is substantially quicker than the rate of manual extraction. PDF Extractor can extract data from multiple PDFs at the same time, so if a batch needs processing they can be imported into the tool all at once, saving further time.
Ability to address match extracted data
A unique feature of PDFx is its address matching capability. Addresses published in investment brochures are not always accurate or the same as the postal addresses, which can create problems for future record keeping and the ability to pin other data sets against the property record. By address matching we can return the accurate geo-location with UPRN if required to maintain accuracy of client data sets.
Ability to review and amend extracted data points
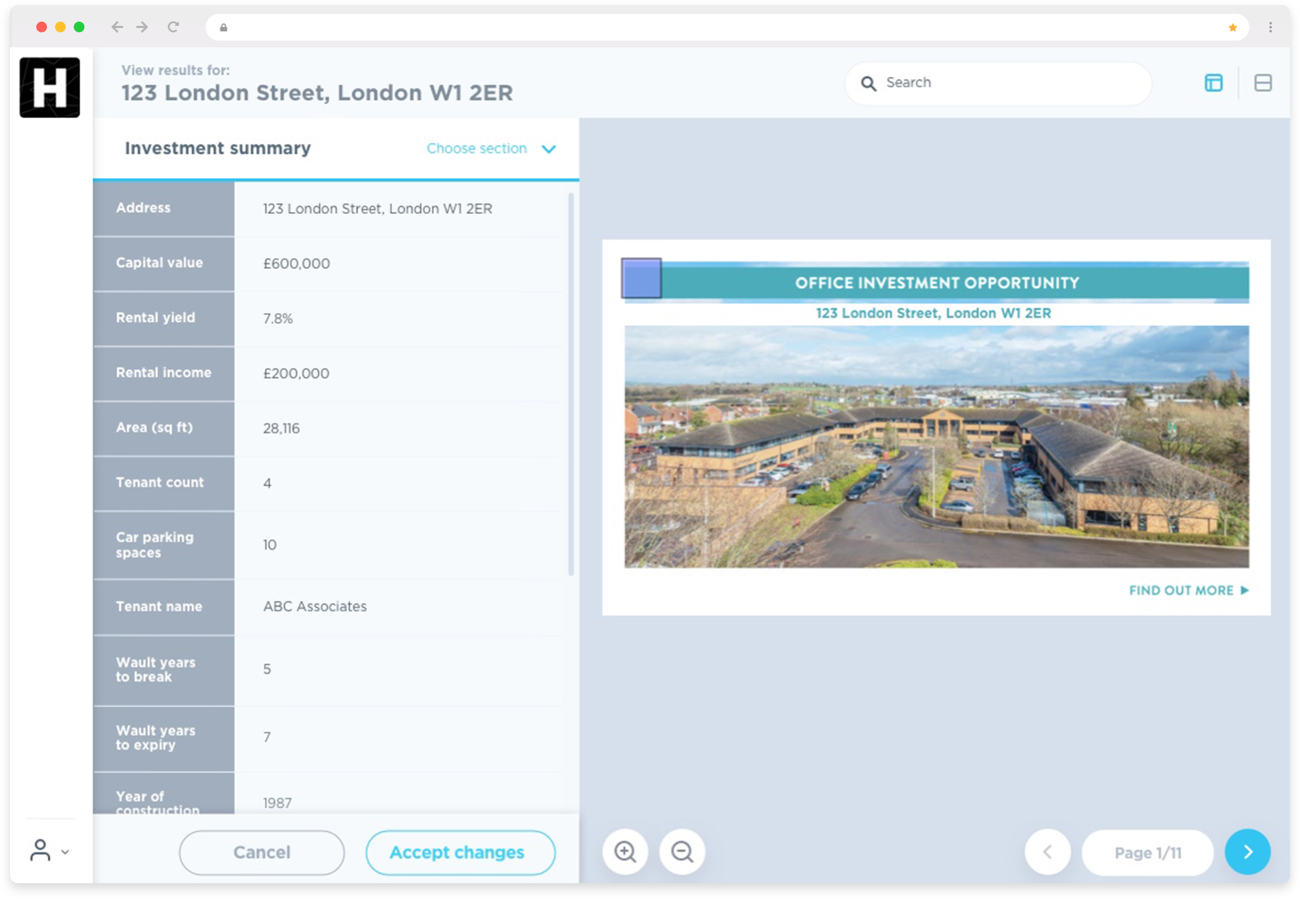
The self-service platform of PDF Extractor allows users to review extracted data points, and cross reference them with the original datapoint in the extracted brochure. By clicking on a data point the tool highlights where in the initial document the data was extracted from. Users can also manually edit and amend data points if they wish, meaning that when the data is extracted as an csv file or imported into their CRM the amends are retained.
To find out more about PDF Extractor click here, or to book a demo contact enquiries@harnessproperty.com.
Slice of type related_articles